
Supervised vs Unsupervised Learning
Or: the question that should’ve been asked in week one.

I once watched a my opposite team spend most of a quarter building what they kept calling a “churn prediction model” before the question that killed the project finally got asked out loud, in a Tuesday standup, by the new hire where are the labels actually coming from?
Nobody had a good answer. They had usage logs. They had a vague sense that “churned” meant “hasn’t logged in for a while.” They did not have a dataset where someone, somewhere, had written down this customer churned, this one didn’t in a way a model could learn from. They’d been building a supervised learning project on top of unsupervised data and calling the gap a detail to figure out later.
I bring this up because almost every explainer treats supervised and unsupervised learning like two flavors of ice cream. Pick the one you feel like. That framing is how you end up in that Tuesday standup.
They aren’t two flavors. They’re answers to two completely different questions, and the question you’re actually asking determines everything else what data you need, how long the project takes, whether it’s even possible.
The short version
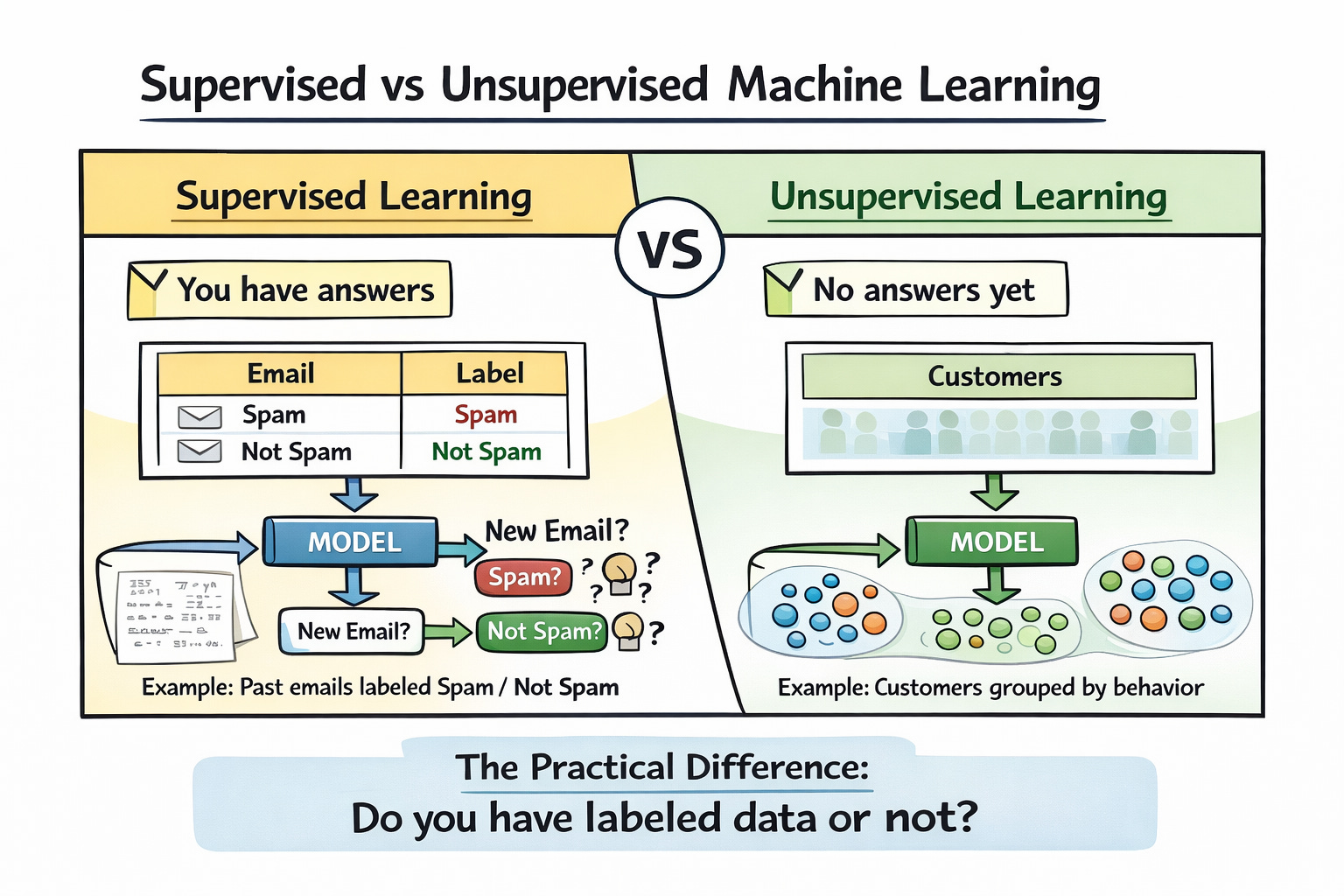
Supervised learning needs an answer key. You show a model thousands of examples where you already know the right answer, and it learns to reproduce that answer on examples it hasn’t seen. Spam filter, as here are 50,000 emails a human labeled “spam” or “not spam,” now go filter my inbox. House price model, and here are the last ten years of sales, now tell me what mine is worth.
Unsupervised learning has no answer key. You hand it data and ask it to find structure nobody told it was there. Segment these users into groups that behave alike. Compress these 10,000 features into 20 that matter. Flag the ones that look nothing like the rest.
That’s the whole distinction. Everything else is downstream.
Why the answer-key thing matters more than it sounds?
The reason supervised learning dominates production ML isn’t that it’s smarter. It’s that having a clean target makes the whole problem tractable. You can measure whether you’re winning. You can A/B test. You can point at a number and tell your boss it went up.
The price you pay is labels. Somebody has to create them, and that somebody is usually either expensive (a radiologist tagging tumor scans) or slow (a team of contractors annotating images for six months) or unreliable (crowdworkers who guess when they’re bored). A huge chunk of real ML work is not modeling. It’s arguing about what the label should even mean and then convincing someone to pay for enough of them.
This is why the churn team got stuck. “Churned” isn’t a fact in the database. It’s a definition someone has to commit to. Is it 30 days inactive? 60? Did they cancel, or did they just ghost? Every answer makes a different dataset, and the model can only learn whichever one you picked. Nobody wanted to pick, so the project floated.
What unsupervised learning is actually good for
Unsupervised learning gets undersold because it doesn’t produce the kind of clean number you can put in a slide. It produces understanding, which is harder to defend in a quarterly review.
The first time you look at a new dataset and have no idea what’s in it. Run a clustering algorithm, look at the clusters, figure out what the groups represent, and now you have a vocabulary for talking about your data. Most customer segmentation starts this way, even if the final version is hand-tuned afterward.
When you have way too many features and suspect most of them are noise. Dimensionality reduction (PCA, UMAP, autoencoders depending on how you’re feeling) squeezes the data down to something you can actually plot or feed into a smaller model. Biologists use this constantly to make sense of gene expression data with 20,000 variables per sample.
When you want to flag the weird stuff. Fraud detection, manufacturing defects, server anomalies. You don’t know what fraud will look like tomorrow, so you can’t label it in advance. You learn what “normal” looks like and scream when something deviates.
The REAL thing is evaluating unsupervised models is a nightmare. Your clusters might be mathematically gorgeous and tell you absolutely nothing useful about your business. There’s no test set, no accuracy score, no clean win condition. You’re relying on someone with domain knowledge to look at the output and say “yes, that’s meaningful” or “no, that’s noise.” People forget this and then wonder why their clustering project never shipped.
So which one do you use
The question to ask, before anything else, is do I know what I’m trying to predict, and do I have (or can I cheaply get) examples of the right answer?
If yes, you’re in supervised territory. Don’t be clever about it. Pick a baseline model, train it, see how it does.
If no if you’re trying to understand what’s in your data, or explore, or find groupings, or reduce complexity you’re in unsupervised territory. Use it to figure out what question is even worth asking, and then maybe build a supervised model on top once you’ve learned enough to define the target.
The mistake I keep seeing is people jumping to supervised learning because that’s what “doing ML” looks like in their head, when they should be doing a week of unsupervised exploration first to figure out what the actual problem is.
The part that complicates everything
This is Where the clean split starts leaking. Most of the AI you’ve actually heard of in the last few years doesn’t fit neatly into either bucket.
Large language models are trained by taking a sentence, hiding the next word, and asking the model to predict it. There are no human labels. The model generates its own training signal from the text itself. This is called self-supervised learning, and it’s basically a trick of unsupervised data, supervised training loop. The same idea shows up in vision models that mask part of an image and reconstruct it.
Semi-supervised learning splits the difference more literally. A small pile of labeled data, a mountain of unlabeled data, and a training process that uses both. Handy when labels are expensive and unlabeled examples are free, which is approximately always.
And then there’s reinforcement learning, which doesn’t really belong in this conversation but always shows up in it. Learning from reward signals instead of labels. Different beast.
If you squint, the real spectrum isn’t supervised versus unsupervised. It’s how much guidance the model is getting, and what form the guidance takes. Human labels are the strongest, most expensive signal. Self-generated prediction tasks are weaker but infinitely scalable. Pure clustering is weakest but requires nothing but the data itself. Modern systems mix and match freely.
The part to remember
Before you touch a model, before you pick an algorithm, before you open a notebook, answer one question do I know the answer I’m looking for, or am I trying to find out what answers exist at all?
If you know, you need labels, and the hard work is getting them.
If you don’t, you need exploration, and the hard work is figuring out what you’ve actually found.
Getting this wrong costs quarters. That churn team eventually shipped something, but only after they stopped calling it prediction and admitted they were doing segmentation.
Reply and tell me about a project where you got this wrong I collect these, they’re usually funnier in hindsight. If you want more of this kind of thing in your inbox, subscribe below.